Code
library(tidyverse)
library(tidymodels)
library(vip)library(tidyverse)
library(tidymodels)
library(vip)v5_dat <- readRDS(here::here("Data", "v5_dat.rds"))
startup_costs <- readRDS(here::here("Data", "startup_costs.rds"))source(here::here("Scripts", "get_startup.R"))v5_dat_wide <- v5_dat |>
# condensing denominator neglect scores down to one score per item pair
mutate(.by = c(subject_id, item),
score = ifelse(task == "dn.c" | task == "dn.s",
mean(score),
score)) |>
unique() |>
select(-c(time, task)) |>
pivot_wider(names_from = "item", values_from = "score",
id_cols = c(subject_id, sscore)) |>
# alert alert !!
drop_na()set.seed(1234)
# splitting data
v5_dat_split <- initial_split(v5_dat_wide)
v5_dat_train <- training(v5_dat_split)
v5_dat_test <- testing(v5_dat_split)
# building "recipe" of all items regressed on sscore
v5_dat_recipe <- recipe(sscore ~ ., data = v5_dat_train) |>
# not including subject_id
update_role(subject_id, new_role = "ID") |>
# and z-scoring first
step_normalize(all_numeric(), -all_outcomes())
# linear regression with glmnet, mixture = 1 to do LASSO
lasso_spec <- linear_reg(penalty = 0.1, mixture = 1) %>%
set_engine("glmnet")
wf <- workflow() %>%
add_recipe(v5_dat_recipe)
# fitting model with training data
lasso_fit <- wf %>%
add_model(lasso_spec) %>%
fit(data = v5_dat_train)
# extracting estimates
lasso_estimates <- lasso_fit %>%
extract_fit_parsnip() %>%
tidy()
# display estimates
# lasso_estimates |>
# filter_out(when_any(estimate == 0,
# term == "(Intercept)")) |>
# mutate(task = term |> str_split_i("_", 1)) |>
# select(task, item = term, estimate)lasso_estimates |>
filter(estimate != 0 & term != "(Intercept)") |>
mutate(task = str_split_i(term, "_", 1)) |>
ggplot(aes(y = fct_reorder(term, abs(estimate)), x = abs(estimate),
color = task)) +
geom_point() +
annotate("segment", x = 0.05, y = -Inf, yend = Inf, alpha = 0.2) +
scale_x_continuous(breaks = c(0, 0.05, 0.1)) +
coord_cartesian(xlim = c(0, 0.1)) +
labs(x = "Absolute Estimate", y = NULL, color = "Task",
title = "Non-Zero Estimates") +
theme_classic() +
theme(aspect.ratio = 3)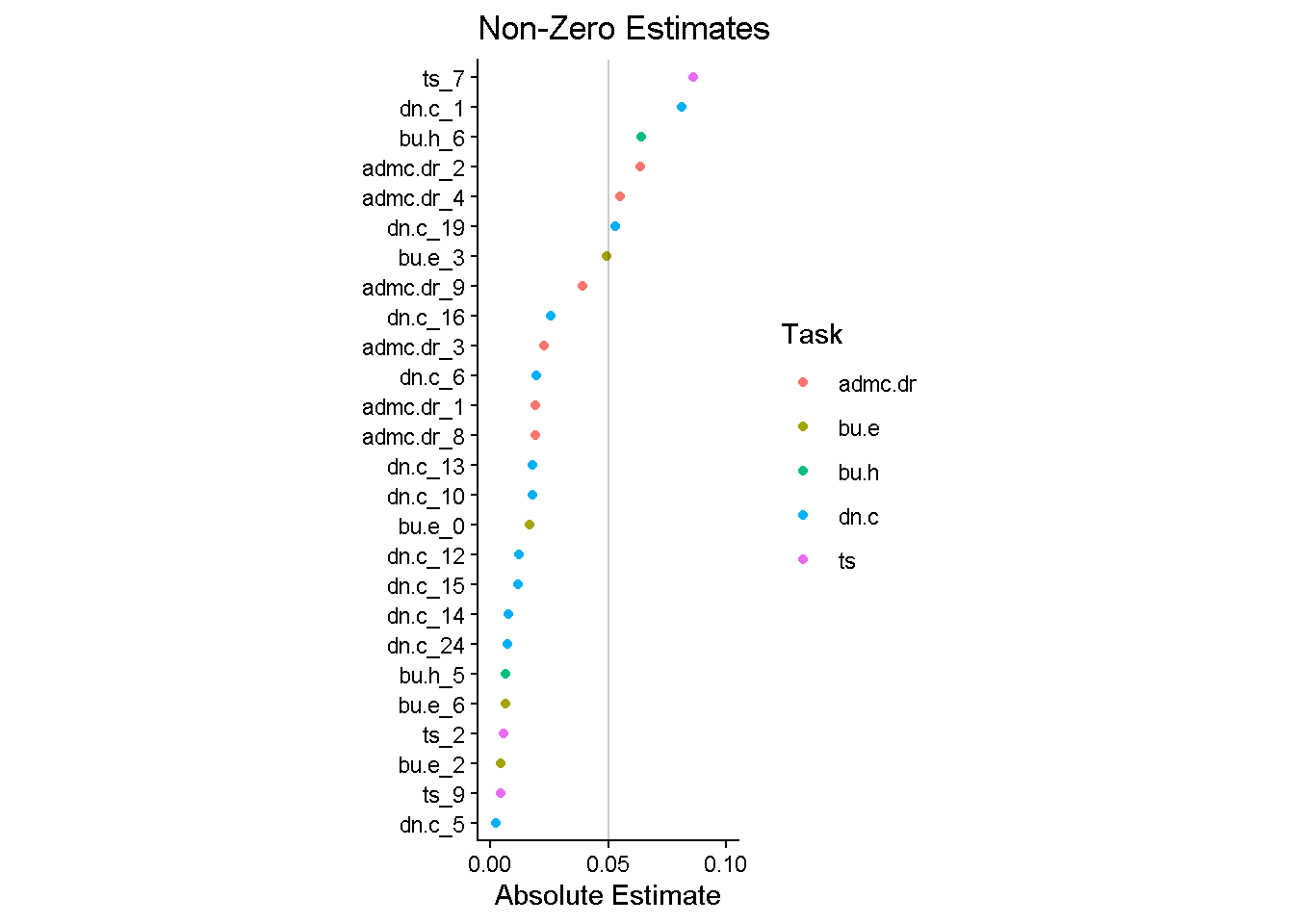
lasso_test_time <- lasso_estimates |> filter(estimate != 0 & term != "(Intercept)") |>
mutate(task = str_split_i(term, "_", 1)) |>
inner_join(v5_dat |> select(item, time) |> unique(),
join_by("term" == "item")) |>
summarize(.by = task,
time = sum(time) + get_startup(first(task))) |>
summarize(time = sum(time)) |>
pull(time)Time of LASSO test: 16.31 minutes.
Trying some tuning with the penalty argument to see if it makes a difference!
# tune penalty instead of fixing it
tune_spec <- linear_reg(penalty = tune(), mixture = 1) %>%
set_engine("glmnet")set.seed(1234)
v5_dat_boot <- bootstraps(v5_dat_train)
lambda_grid <- grid_regular(penalty(), levels = 50)
doParallel::registerDoParallel()
set.seed(2020)
lasso_grid <- tune_grid(
wf %>% add_model(tune_spec),
resamples = v5_dat_boot,
grid = lambda_grid
)
saveRDS(lasso_grid, here::here("Data", "lasso-estimates_tuning.rds"))lasso_grid <- readRDS(here::here("Data", "lasso-estimates_tuning.rds"))
lasso_grid %>%
collect_metrics() %>%
ggplot(aes(penalty, mean, color = .metric)) +
geom_errorbar(aes(
ymin = mean - std_err,
ymax = mean + std_err),
alpha = 0.5) +
geom_line(linewidth = 1.5, na.rm = T) +
facet_wrap(~.metric, scales = "free", nrow = 2) +
scale_x_log10() +
theme_classic() +
theme(legend.position = "none")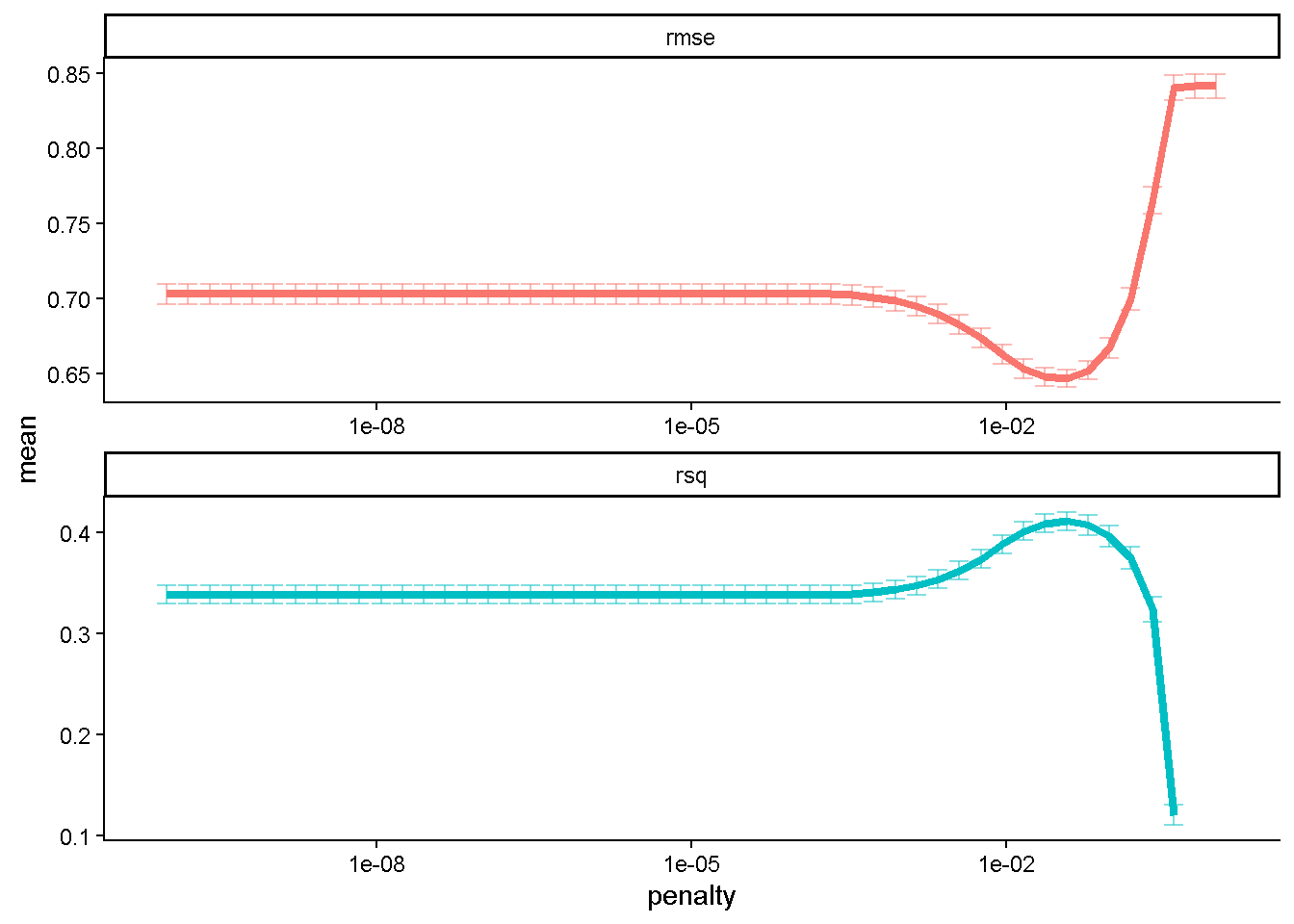
lowest_rmse <- lasso_grid %>%
select_best(metric = "rmse")
final_lasso <- finalize_workflow(
wf %>% add_model(tune_spec),
lowest_rmse
)
final_lasso %>%
fit(v5_dat_train) %>%
extract_fit_parsnip() %>%
vi() |>
saveRDS(here::here("Data", "lasso_regression.rds"))
final_lasso %>%
fit(v5_dat_train) %>%
extract_fit_parsnip() %>%
vi(lambda = lowest_rmse$penalty) %>%
filter_out(Importance == 0) |>
mutate(task = str_split_i(Variable, "_", 1)) |>
mutate(
Importance = abs(Importance),
Variable = fct_reorder(Variable, Importance)
) %>%
ggplot(aes(x = Importance, y = Variable, color = task)) +
geom_point() +
labs(y = NULL, color = "Task", title = "Non-Zero Estimates", x = "Absolute Estimate") +
annotate("segment", x = 0.05, y = -Inf, yend = Inf, alpha = 0.2) +
scale_x_continuous(breaks = c(0, 0.05, 0.1)) +
coord_cartesian(xlim = c(0, 0.1)) +
theme_classic() +
theme(aspect.ratio = 3)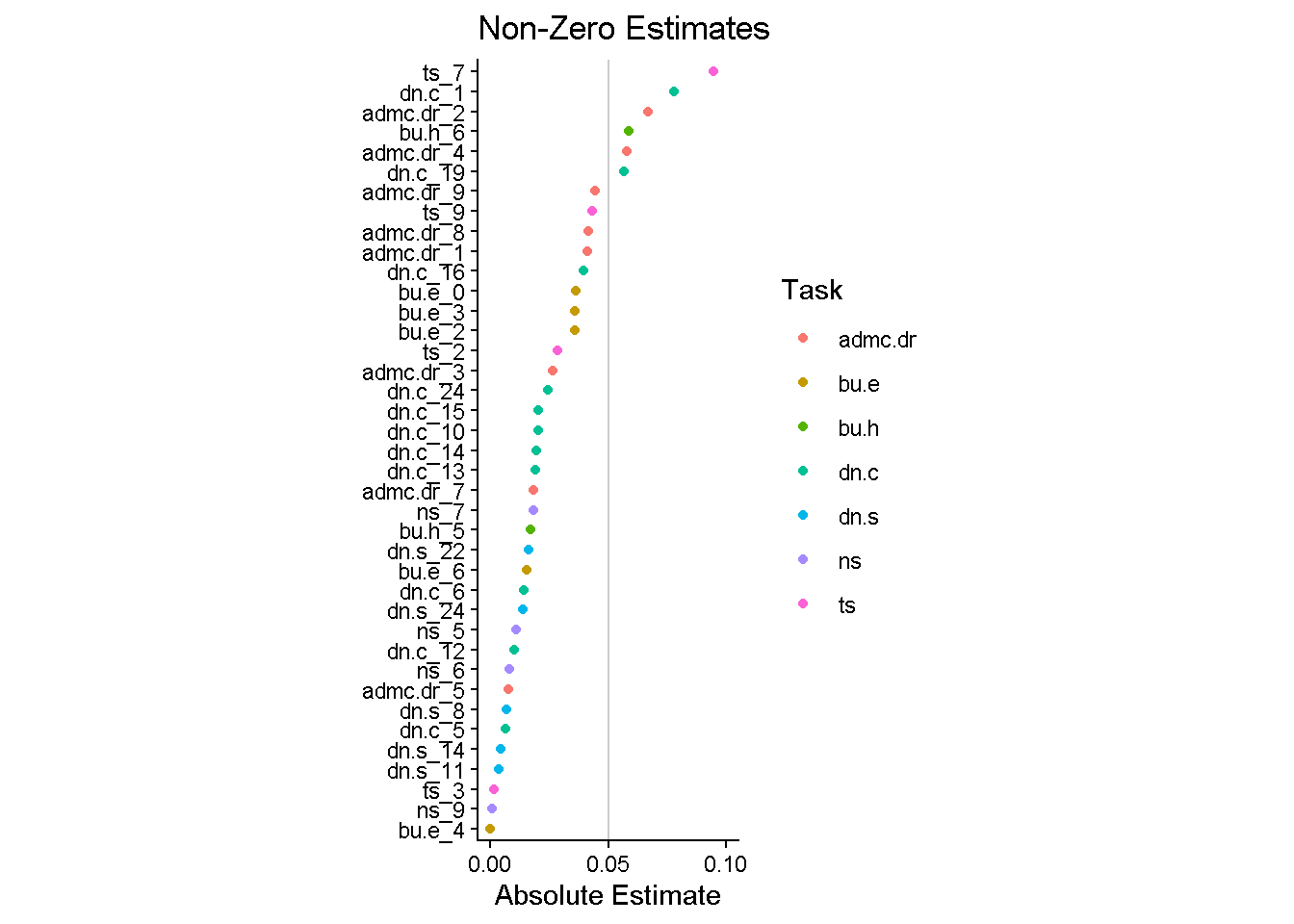
lasso_tuned_test_time <- final_lasso %>%
fit(v5_dat_train) %>%
extract_fit_parsnip() |>
tidy() |>
filter(estimate != 0 & term != "(Intercept)") |>
mutate(task = str_split_i(term, "_", 1)) |>
inner_join(v5_dat |> select(item, time) |> unique(),
join_by("term" == "item")) |>
summarize(.by = task,
time = sum(time) + get_startup(first(task))) |>
summarize(time = sum(time)) |>
pull(time)Time of tuned LASSO test: 21.66 minutes.
lasso_estimates |>
filter(estimate != 0 & term != "(Intercept)") |>
mutate(task = str_split_i(term, "_", 1)) |>
ggplot(aes(y = fct_reorder(term, abs(estimate)), x = abs(estimate),
color = task)) +
geom_point() +
annotate("segment", x = 0.05, y = -Inf, yend = Inf, alpha = 0.2) +
scale_x_continuous(breaks = c(0, 0.05, 0.1)) +
coord_cartesian(xlim = c(0, 0.1)) +
labs(x = "Absolute Estimate", y = NULL, color = "Task",
title = "No Tuning") +
theme_classic() +
theme(aspect.ratio = 3)
final_lasso %>%
fit(v5_dat_train) %>%
extract_fit_parsnip() %>%
vi(lambda = lowest_rmse$penalty) %>%
filter_out(Importance == 0) |>
mutate(task = str_split_i(Variable, "_", 1)) |>
mutate(
Importance = abs(Importance),
Variable = fct_reorder(Variable, Importance)
) %>%
ggplot(aes(x = Importance, y = Variable, color = task)) +
geom_point() +
labs(y = NULL, color = "Task", title = "Tuning", x = "Absolute Estimate") +
annotate("segment", x = 0.05, y = -Inf, yend = Inf, alpha = 0.2) +
scale_x_continuous(breaks = c(0, 0.05, 0.1)) +
coord_cartesian(xlim = c(0, 0.1)) +
theme_classic() +
theme(aspect.ratio = 3)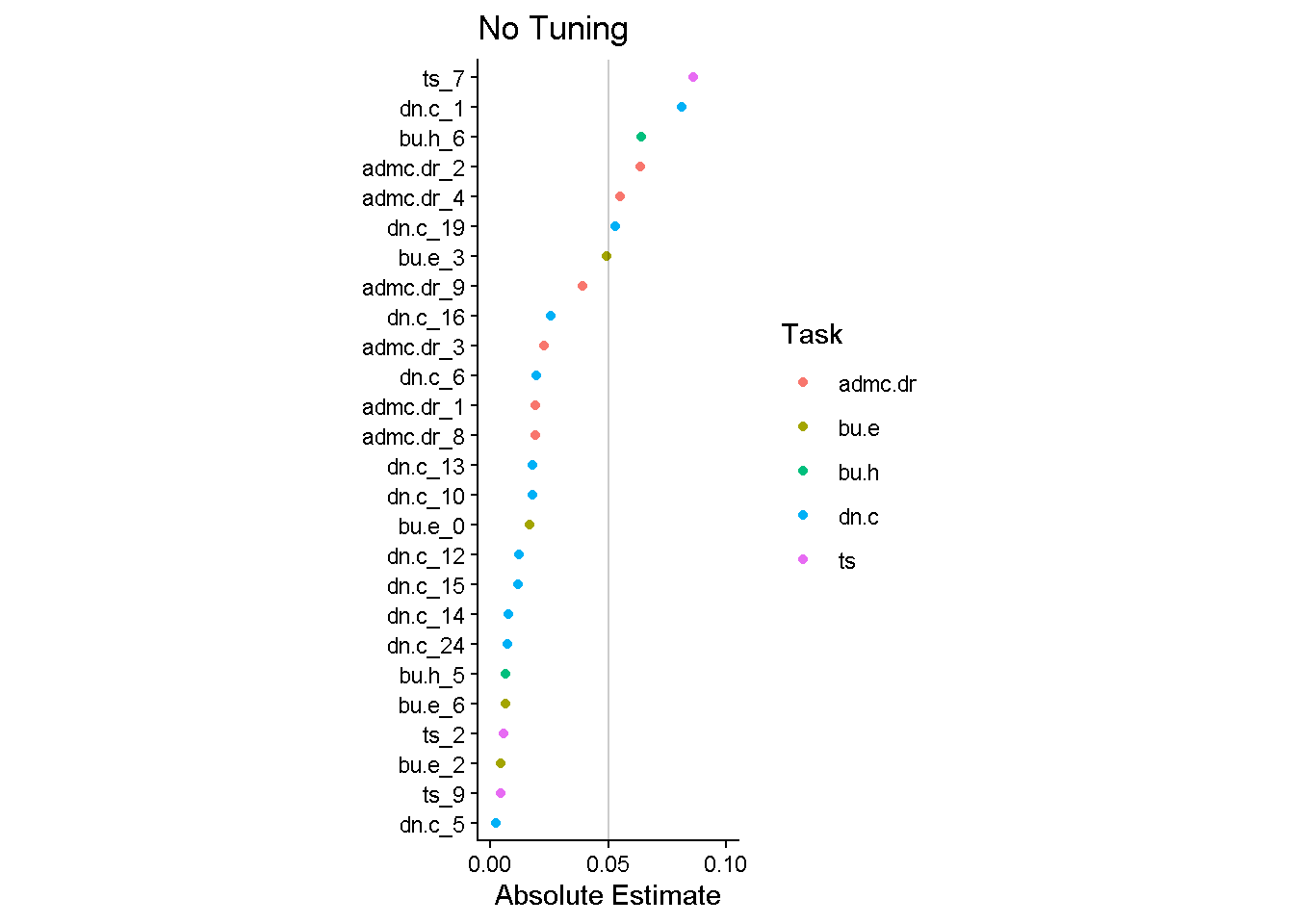
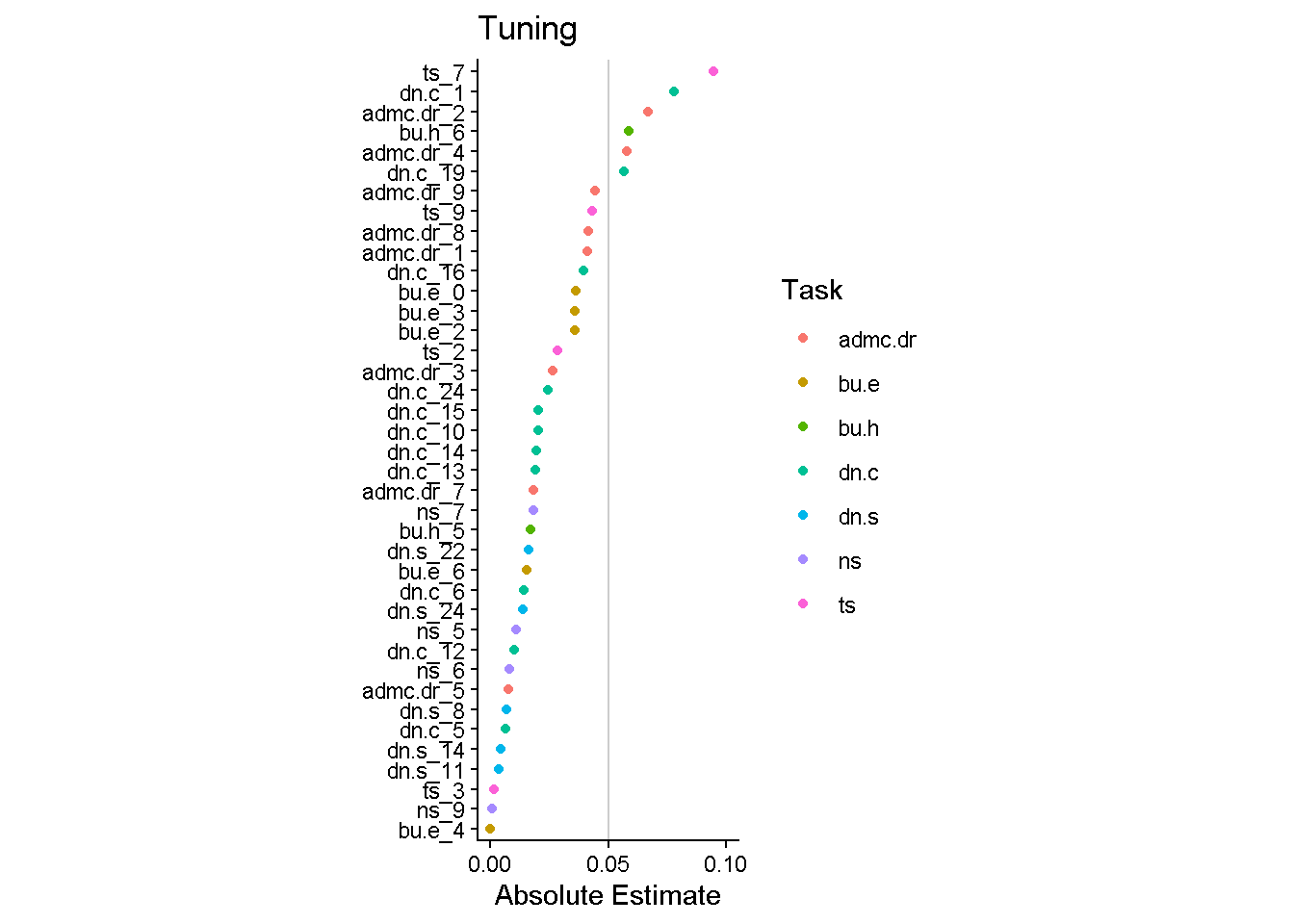
cor_including_zeros <- full_join(
lasso_fit %>%
extract_fit_parsnip() |>
vi() %>%
select(importance_notuning = Importance, Variable),
final_lasso %>%
fit(v5_dat_train) %>%
extract_fit_parsnip() %>%
vi(lambda = lowest_rmse$penalty) %>%
select(importance_tuning = Importance, Variable),
by = "Variable"
) |>
summarize(cor = cor(importance_notuning, importance_tuning))
cor_not_including_zeros <- full_join(
lasso_fit %>%
extract_fit_parsnip() |>
vi() %>%
filter_out(Importance == 0) |>
select(importance_notuning = Importance, Variable),
final_lasso %>%
fit(v5_dat_train) %>%
extract_fit_parsnip() %>%
vi(lambda = lowest_rmse$penalty) %>%
filter_out(Importance == 0) |>
select(importance_tuning = Importance, Variable) ,
by = "Variable"
) |>
summarize(cor = cor(importance_notuning, importance_tuning, use = "complete"))Looks like more items included for the tuned model. Relatively similar top items. Correlation between estimates including all the zeros is 0.5442897 and without all the zeros (dropping those items) is 0.8265207.