Code
library(tidyverse)Search Algorithm
library(tidyverse)dn_dat_c <- readRDS(here::here("Data", "Denominator Neglect", "dn_dat_c.rds"))
bu_dat_h <- readRDS(here::here("Data", "Bayesian Update", "bu_dat_h.rds"))
admc.dr_dat <- readRDS(here::here("Data", "ADMC Decision Rules", "admc.dr_dat.rds"))
ns_dat <- readRDS(here::here("Data", "Number Series", "ns_dat.rds"))
dn_top_items <- readRDS(here::here("Data", "Denominator Neglect", "top_items.rds"))dn_dat_c <- dn_dat_c |>
left_join(dn_top_items |>
pivot_longer(c(conf_item, harm_item),
names_to = "choice_type", values_to = "item") |>
select(item, rank),
by = "item") |>
mutate(task = "dn.c",
item = paste0(task, "_", rank),
# still need time per item
time = 3.43 / (length(unique(item)) * 2),
score = correct,
.keep = "unused") |>
select(subject_id, sscore, task, item, score, time)bu_dat_h <- bu_dat_h |>
mutate(task = "bu.h",
item = paste0(task, "_", unique_trial),
time = 6.56 / length(unique(item)),
.keep = "unused") |>
select(subject_id, sscore, task, item, score, time)admc.dr_dat <- admc.dr_dat |>
mutate(task = "admc.dr",
item = paste0(task, "_", admc_id),
time = 5.87 / length(unique(item)),
.keep = "unused") |>
select(subject_id, sscore, task, item, score, time)ns_dat <- ns_dat |>
mutate(task = "ns",
item = paste0(task, "_", ns_id),
time = 3.70 / length(unique(item)),
.keep = "unused") |>
select(subject_id, sscore, task, item, score, time)v3_dat <- rbind(dn_dat_c,
bu_dat_h,
admc.dr_dat,
ns_dat)Note that all time information is based on the median time (from FPT preprint) for the entire task divided by number of items.
The FPT Version 3 includes five cognitive tasks.
Denominator Neglect: Combined
Bayesian Update: Hard
ADMC: Decision Rules
Number Series
Cognitive Reflection Test
I don’t know what to do with the CRT as of now, so this will only have Denominator Neglect: Combined, Bayesian Update: Hard, ADMC: Decision Rules, Number Series.
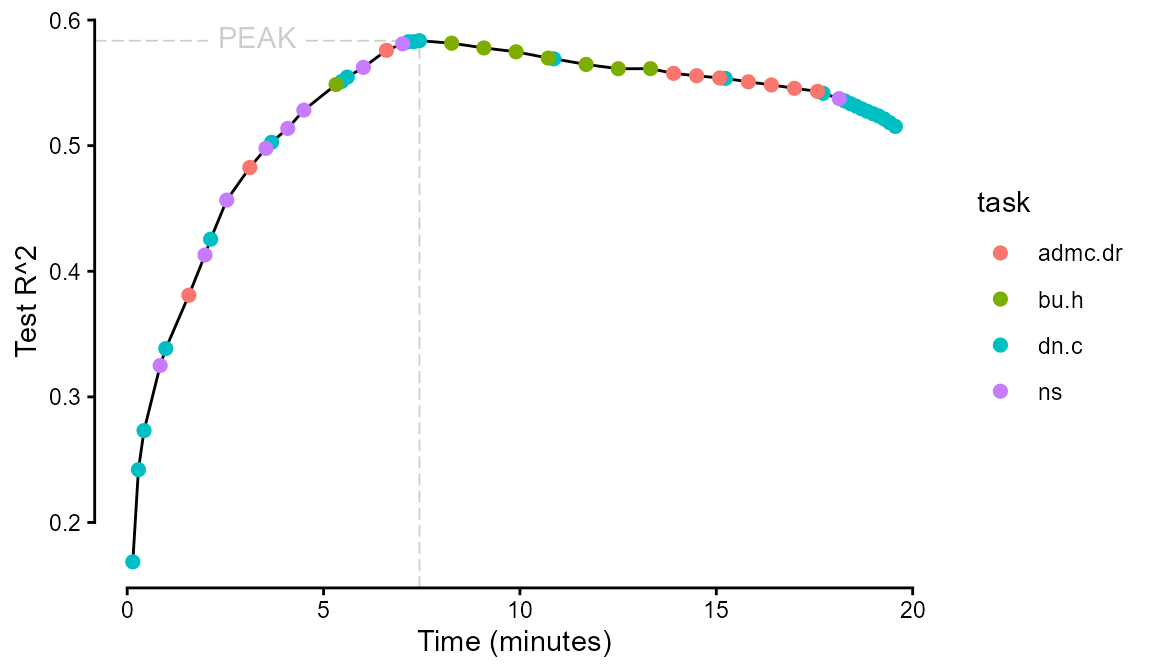
This algorithm seeks to maximize the \(R^2\) of predicting s-scores per minute for a set of cognitive task items of average testing time t.
test <- data.frame(rep = 0,
task = "INIT",
item = "INIT",
test_r2 = 0,
time = 0,
added_r2 = 0,
added_time = 0,
r2_rate = 0)
walk(seq(1, v3_dat |> pull(item) |> unique() |> length()),
\(i) {test <<- v3_dat |>
filter(!(item %in% pull(test, item))) |>
pull(item) |>
unique() |>
map(~ rbind(v3_dat |>
filter(item == .x),
v3_dat |>
filter(item %in% pull(test, item))) |>
summarize(.by = c(task, subject_id),
score = mean(score),
sscore = first(sscore),
time = sum(time),
task = first(task)) |>
mutate(.by = subject_id,
time = sum(time)) |>
mutate(formula = paste("sscore ~", task |> unique() |> paste(collapse = "+"))) |>
pivot_wider(names_from = task, values_from = score) |>
summarize(rep = i,
task = str_split_i(.x, "_", 1),
item = .x,
test_r2 = summary(lm(as.formula(first(formula)),
data = pick(everything())))$r.squared,
added_r2 = first(test_r2) - test |>
head(1) |>
pull(test_r2),
added_time = first(time) - test |>
head(1) |>
pull(time),
time = first(time),
r2_rate = first(added_r2 / added_time))) |>
list_rbind() |>
filter(r2_rate == max(r2_rate)) |>
rbind(test) |>
filter(item != "INIT")},
.progress = T)
test
saveRDS(test, here::here("Data", "Search Algorithms", "v3test_dat.rds"))test <- readRDS(here::here("Data", "Search Algorithms", "v3test_dat.rds"))test |>
ggplot(aes(x = time, y = test_r2)) +
geomtextpath::geom_textsegment(data = filter(test, test_r2 == max(test_r2)),
aes(x = -Inf, xend = time, y = test_r2, yend = test_r2, label = "PEAK"),
color = "gray80", linewidth = .3, linetype = "longdash") +
geom_segment(data = filter(test, test_r2 == max(test_r2)),
aes(y = -Inf, yend = test_r2, x = time),
color = "gray80", linewidth = .3, linetype = "longdash") +
geom_line() +
geom_point(aes(color = task), size = 2) +
guides(x = guide_axis(cap = "both"),
y = guide_axis(cap = "both")) +
labs(x = "Time (minutes)", y = "Test R^2") +
theme_classic()