[1] 3.841459[1] 3.841459PSYC 2020-A01 / PSYC 6022-A01 | 2025-11-07 | Lab 12
Learning objectives:
R: \(\chi^2\) Tests
Testing inferences about proportions
○ Involve categorical variables
Comparing observed frequencies (counts) to some expected (null hypothesis) frequencies
\(\chi^2\) Test of Goodness of Fit: expected frequencies are set by researcher (e.g., null hypothesis is equal frequencies across all groups)
\(\chi^2\) Test of Independence: expected frequencies are those implied by independence
Instead of a continuous variable, our outcome is a count
Continuous
Height
Petal length
Test score
Counts
Coin flip being heads
Number of pets
Goals scored
Only integers
Do the observed frequencies of a categorical variable differ from what expected a priori?
Typically, this expectation is equal occurrence across groups (but doesn’t have to be).
If equal occurrence, what would be our expected frequencies?
100 coin flips
| Heads | Tails |
|---|---|
| 50 | 50 |
Favorite primary color of 33 students
| Red | Blue | Yellow |
|---|---|---|
| 11 | 11 | 11 |
Can also hypothesize proportions and convert to frequencies once you have a sample size.
\(H_0\): Observed data match the expected frequencies for the population
\(H_1\): Observed data do not match the expected frequencies for the population
○ Observed frequency is significantly different than expected
\(H_0\): \(\pi_j = \pi_{j_0}\) for all categories \(j\) (i.e., difference for all categories is 0), where
\(\pi_j\) = observed proportion
\(\pi_{j_0}\) = expected proportion
\(H_1\): \(\pi_j \neq \pi_{j_0}\) for any category \(j\)
\[ \chi^2 = \sum_{j=1}^{J} \frac{(O_j – N\pi_{j_0})^2}{N\pi_{j_0}} = \sum_{j=1}^{J} \frac{(O_j – E_j)^2}{E_j} \]
where
\(O_j\) = observed frequency
\(N\) = total sample size
\(E_j\) = expected frequency
\(j\) = individual category out of \(J\) total categories
The sum of the squared differences between the observed and expected frequencies, divided by the expected frequency, for each group.
\(\text{df} = J - 1\), where
\(J\) = number of categories
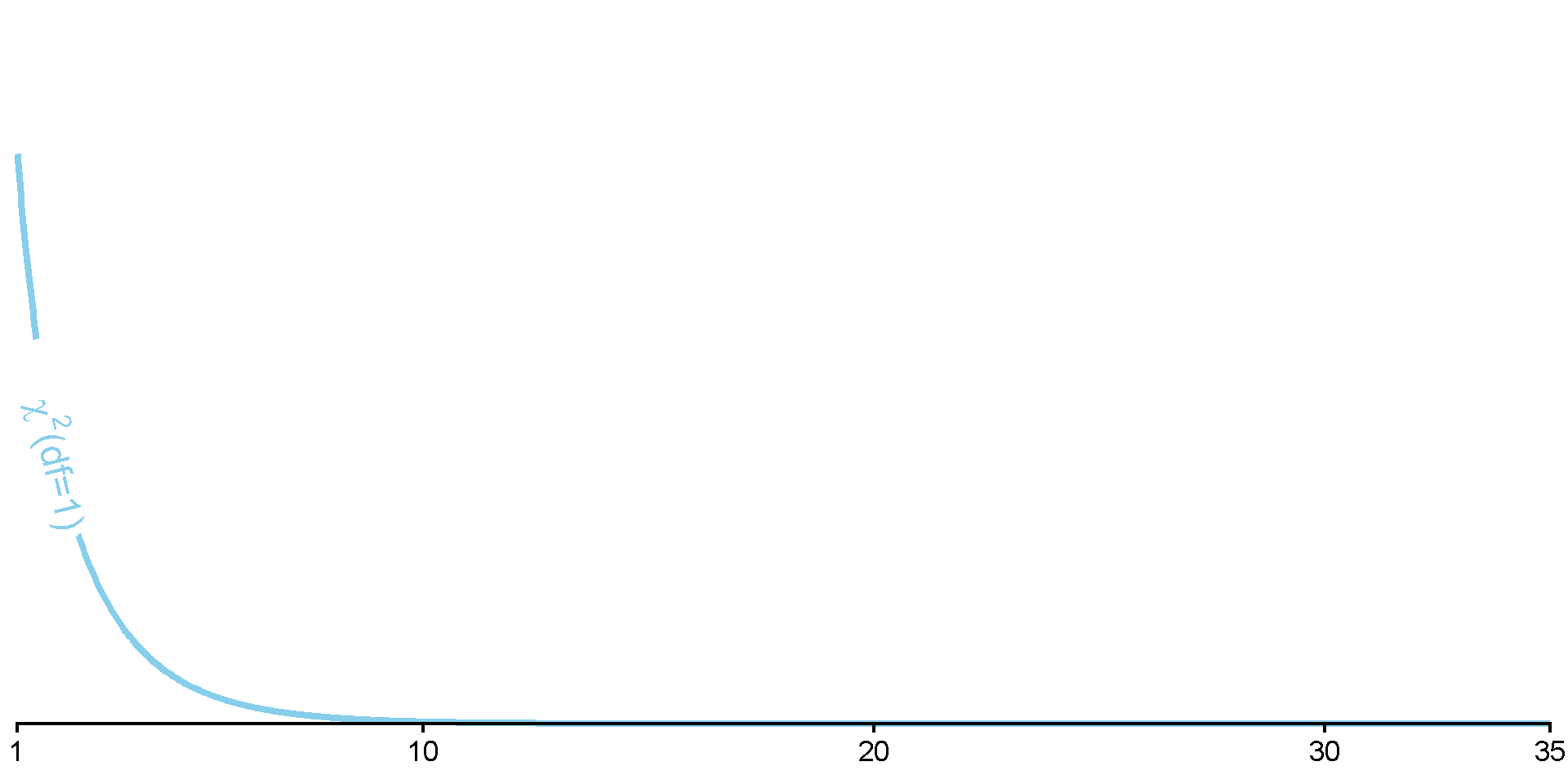
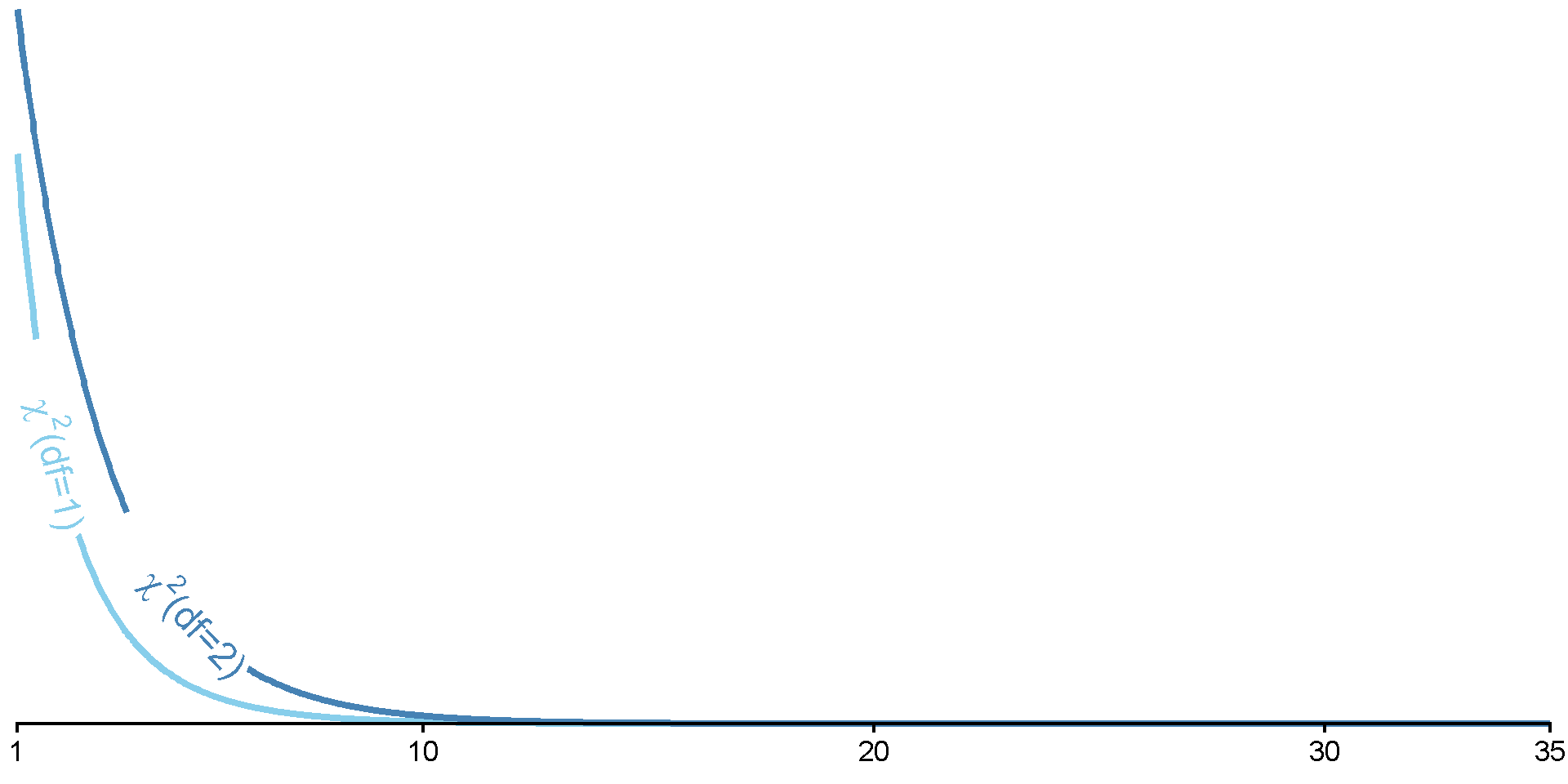
Use to identify critical \(\chi^2\) value from \(\chi^2\) table, R, etc.
For \(\chi^2\), as \(\text{df}\) increases, so does the critical-\(\chi^2\) value (at same \(\alpha\))
Only ever a one-tailed test! For the upper end of the distribution.
Cutoff for test of heads vs. tails
\(J =\) 2
\(\text{df} = J - 1 =\) 1
You are an education psychologist interested in college students’ choice of majors. You’ve grouped majors into five categories: STEM, Social Sciences, Humanities, Arts, and Business. You’d like to test whether there are differences in the population of students choosing those majors. You sample 100 students and ask what major they chose.
First, what are your expected frequencies for each category?
| STEM | Social Sciences | Humanities | Arts | Business | |
|---|---|---|---|---|---|
| Expected | |||||
| Observed |
You are an education psychologist interested in college students’ choice of majors. You’ve grouped majors into five categories: STEM, Social Sciences, Humanities, Arts, and Business. You’d like to test whether there are differences in the population of students choosing those majors. You sample 100 students and ask what major they chose.
First, what are your expected frequencies for each category?
| STEM | Social Sciences | Humanities | Arts | Business | |
|---|---|---|---|---|---|
| Expected | 20 | 20 | 20 | 20 | 20 |
| Observed |
You are an education psychologist interested in college students’ choice of majors. You’ve grouped majors into five categories: STEM, Social Sciences, Humanities, Arts, and Business. You’d like to test whether there are differences in the population of students choosing those majors. You sample 100 students and ask what major they chose.
Next, what is your \(\chi^2\) cutoff value?
| STEM | Social Sciences | Humanities | Arts | Business | |
|---|---|---|---|---|---|
| Expected | 20 | 20 | 20 | 20 | 20 |
| Observed |
Cutoff in R
You are an education psychologist interested in college students’ choice of majors. You’ve grouped majors into five categories: STEM, Social Sciences, Humanities, Arts, and Business. You’d like to test whether there are differences in the population of students choosing those majors. You sample 100 students and ask what major they chose.
Here are the observed values:
| STEM | Social Sciences | Humanities | Arts | Business | |
|---|---|---|---|---|---|
| Expected | 20 | 20 | 20 | 20 | 20 |
| Observed | 65 | 10 | 5 | 5 | 15 |
\[ \chi^2 = \sum_{j=0}^{J} \frac{(O_j – N\pi_j)^2}{N\pi_j} = \sum_{j=0}^{J} \frac{(O_j – E_j)^2}{E_j} \]
We can reject the null in favor of the alternative that the number of students is not the same across majors.
majordat <- data.frame(major = c("STEM", "Social.Sciences", "Humanities", "Arts", "Business"),
observed = c(65, 10, 5, 5, 15))
chisq <- majordat |>
select(observed) |>
chisq.test()
chisq
Chi-squared test for given probabilities
data: select(majordat, observed)
X-squared = 130, df = 4, p-value < 2.2e-16Let’s restart and say that you were a educational psychologist interested in how students in STEM schools choose their major. In this situation, you had expected more students to select a STEM major than other majors.
These are your new expected frequencies (60% STEM, evenly divided across the rest):
| STEM | Social Sciences | Humanities | Arts | Business | |
|---|---|---|---|---|---|
| Expected | 60 | 10 | 10 | 10 | 10 |
| Observed | 65 | 10 | 5 | 5 | 15 |
Chi-squared test for given probabilities
data: c(65, 10, 5, 5, 15)
X-squared = 7.9167, df = 4, p-value = 0.09468
Chi-squared test for given probabilities
data: c(65, 10, 5, 5, 15)
X-squared = 7.9167, df = 4, p-value = 0.09468○ x = data of frequencies
○ p = expected probabilities
○ rescale.p = [T/F], will rescale p to probabilities if you prefer to input frequencies
Do the observed frequencies of a categorical variable differ from what expected via properties of independence?
○ Now considering more than one type of category
○ E.g., Number of pets by cat vs. dog people and undergrad vs. post-graduate
| Cat Person | Dog Person | |
|---|---|---|
| Undergrad | ||
| Post-Graduate |
Expected frequencies calculated from the marginal totals of the contingency table
○ Expected values determined from data
\(H_0\): Categorical Variable 1 and Categorical Variable 2 are independent (i.e., have no association)
\(H_1\): Categorical Variable 1 and Categorical Variable 2 are not independent (i.e., have some association)
○ Do expected frequencies match those expected via independence?
Mathematically the same as before:
\(H_0\): \(\pi_j = \pi_{j_0}\) for all categories \(j\); difference for all categories is 0, where
\(\pi_j\) = observed proportion
\(\pi_{j_0}\) = expected proportion
\(H_1\): \(\pi_j \neq \pi_{j_0}\) for any category \(j\)
Just changing the expected frequencies
\[ \chi^2 = \sum_{j_1=1}^{J_1}\sum_{j_2=1}^{J_2} \frac{(O_j – N\pi_{j_0})^2}{N\pi_{j_0}} = \sum_{j_1=1}^{J_1}\sum_{j_2=1}^{J_2} \frac{(O_j – E_j)^2}{E_j} \]
Basically identical formula to calculate the \(\chi^2\).
The difference is that our expected frequencies \(E_j\) are derived from the data. Just like before, we calculate the difference from each cell, but now we have two categories that make up the cell.
The sum of the squared differences between the observed and expected frequencies, divided by the expected frequency, for each cell.
What is the critical \(\chi^2\) value in a test of independence for a 3x2?
\(\text{df} = (J_1 - 1) \times (J_2 - 1)\) or
\(\text{df} = (n_{rows} - 1) \times (n_{cols} - 1)\)
You are another educational psychologist, and you’re interested in examining your department’s student body makeup. You wonder whether there is an association between students’ level (graduate vs. undergraduate) and whether they are an in-state student or not. You sample 50 students from your department, and these are the frequencies you observe.
| In-State | Out-of-State | |
|---|---|---|
| Undergrad | 25 | 10 |
| Graduate | 5 | 10 |
First, what are your expected frequencies for each category?
First, get the marginal totals for each column
| In-State | Out-of-State | Total | |
|---|---|---|---|
| Undergrad | 25 | 10 | |
| Graduate | 5 | 10 | |
| Total |
First, get the marginal totals for each column
| In-State | Out-of-State | Total | |
|---|---|---|---|
| Undergrad | 25 | 10 | 35 |
| Graduate | 5 | 10 | 15 |
| Total | 30 | 20 | 50 |
| In-State | Out-of-State | Total | |
|---|---|---|---|
| Undergrad | 25 | 10 | 35 |
| Graduate | 5 | 10 | 15 |
| Total | 30 | 20 | 50 |
| In-State | Out-of-State | Total | |
|---|---|---|---|
| Undergrad | 21 | 14 | 35 |
| Graduate | 9 | 6 | 15 |
| Total | 30 | 20 | 50 |
Expected cell frequency = \(E_j\) = \(\frac{\text{column total} \times \text{row total}}{N}\)
○ Undergrad & In-State = \(\frac{35 \times 30}{50} = 21\)
○ Undergrad & Out-of-State = \(\frac{35 \times 20}{50} = 14\)
○ Graduate & In-State = \(\frac{15 \times 30}{50} = 9\)
○ Graduate & Out-of-State = \(\frac{15 \times 20}{50} = 6\)
\[ \chi^2 = \sum_{j=0}^{J} \frac{(O_j – N\pi_j)^2}{N\pi_j} = \sum_{j=0}^{J} \frac{(O_j – E_j)^2}{E_j} \]
○ correct = [T/F], applies a “continuity correction” to the \(\chi^2\) value. Default is T. Change to F!
We can reject the null in favor of the alternative that students’ level (graduate vs. undergraduate) and whether they are an in-state student or not are not independent.
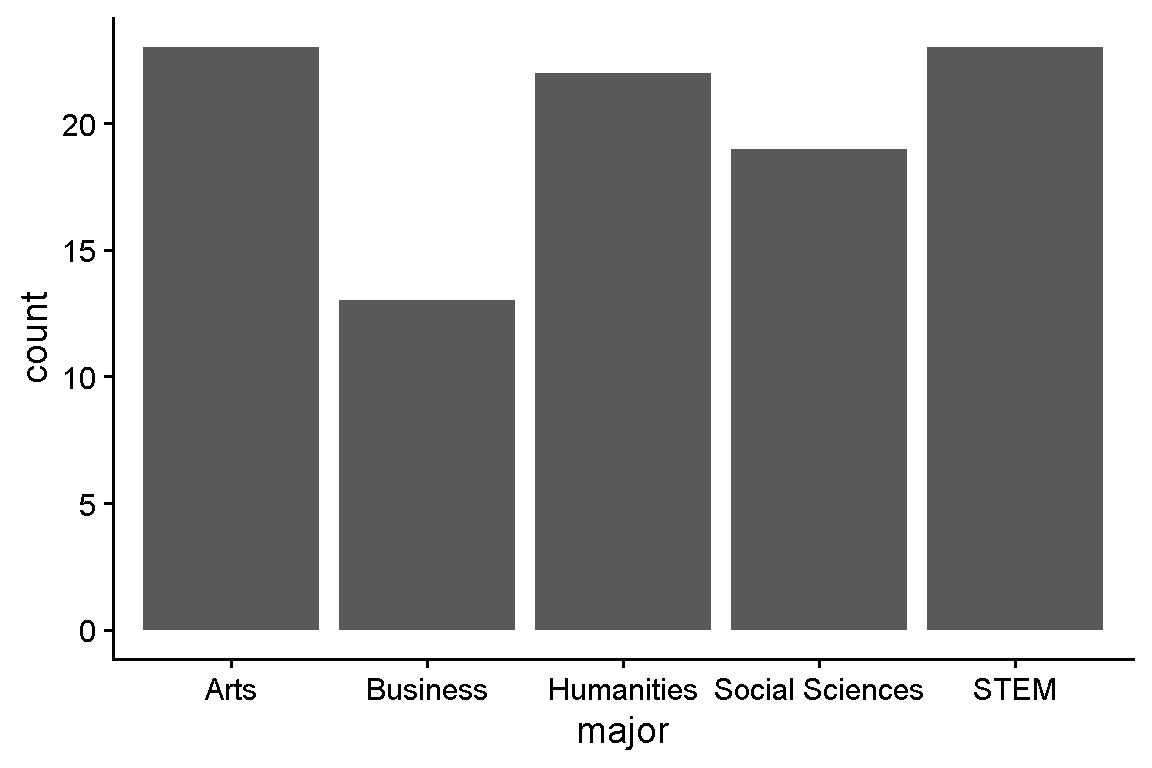
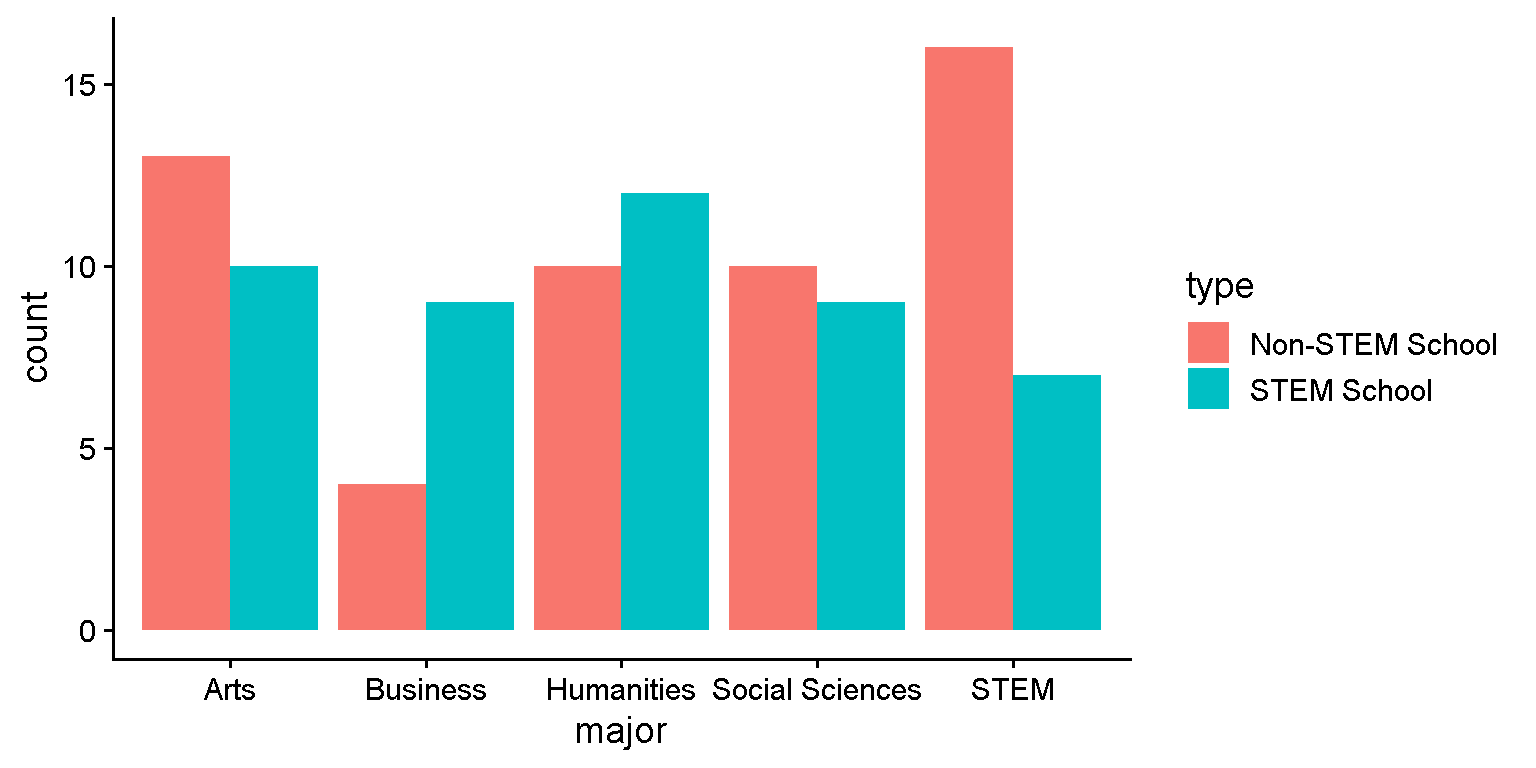
student major type
1 1 STEM Non-STEM School
2 2 Humanities STEM School
3 3 Humanities STEM School
4 4 Social Sciences Non-STEM School
5 5 Humanities STEM School
6 6 Arts Non-STEM School
7 7 Social Sciences STEM School
8 8 Social Sciences STEM School
9 9 STEM STEM School
10 10 STEM STEM School
11 11 Business STEM School
12 12 Social Sciences STEM Schooltable()Some ways to generate frequencies from categorical variables
table() Var1 Var2 Freq
1 Arts Non-STEM School 13
2 Business Non-STEM School 4
3 Humanities Non-STEM School 10
4 Social Sciences Non-STEM School 10
5 STEM Non-STEM School 16
6 Arts STEM School 10
7 Business STEM School 9
8 Humanities STEM School 12
9 Social Sciences STEM School 9
10 STEM STEM School 7summarize()Some ways to generate frequencies from categorical variables
major type n
1 STEM Non-STEM School 16
2 Humanities STEM School 12
3 Social Sciences Non-STEM School 10
4 Arts Non-STEM School 13
5 Social Sciences STEM School 9
6 STEM STEM School 7
7 Business STEM School 9
8 Humanities Non-STEM School 10
9 Arts STEM School 10
10 Business Non-STEM School 4 major type n
1 Arts Non-STEM School 13
2 Arts STEM School 10
3 Business Non-STEM School 4
4 Business STEM School 9
5 Humanities Non-STEM School 10
6 Humanities STEM School 12
7 STEM Non-STEM School 16
8 STEM STEM School 7
9 Social Sciences Non-STEM School 10
10 Social Sciences STEM School 9count()count(x, grouping_var1, grouping_var2, etc.)
○ x = dataframe
grouping_vars = variable names to group by
Basically shorthand for:
Also seems to arrange by default
count()count(x, grouping_var1, grouping_var2, etc.)
○ x = dataframe
grouping_vars = variable names to group by
major type n
1 STEM Non-STEM School 16
2 Humanities STEM School 12
3 Social Sciences Non-STEM School 10
4 Arts Non-STEM School 13
5 Social Sciences STEM School 9
6 STEM STEM School 7
7 Business STEM School 9
8 Humanities Non-STEM School 10
9 Arts STEM School 10
10 Business Non-STEM School 4 major type n
1 Arts Non-STEM School 13
2 Arts STEM School 10
3 Business Non-STEM School 4
4 Business STEM School 9
5 Humanities Non-STEM School 10
6 Humanities STEM School 12
7 STEM Non-STEM School 16
8 STEM STEM School 7
9 Social Sciences Non-STEM School 10
10 Social Sciences STEM School 9summarize()If going to put into the chisq.test() function, want to pivot and get rid of additional columns.
Many ways to do this, but one example:
geom_bar()geom_bar()